
Omnichannel Attribution for B2B: GA4, Social & Offline
Measure B2B marketing ROI in a cookieless world. How to combine GA4, social, and offline touchpoints into one attribution model that reflects how buyers buy.
Updated May 20, 2026

ChatGPT, Perplexity, and Gemini each convert different buyers in different funnels. Here's how to pick the one that actually moves your numbers.
Strip away the mystique, and an LLM is a pattern machine, trained on enormous amounts of text to predict the next likely word.
What that buys you in practice is software that can read natural language and answer in it.
The chat that used to need a human can now qualify a B2B lead from a transcript, draft the follow-up, summarize objections, or explain your refund policy in plain English.
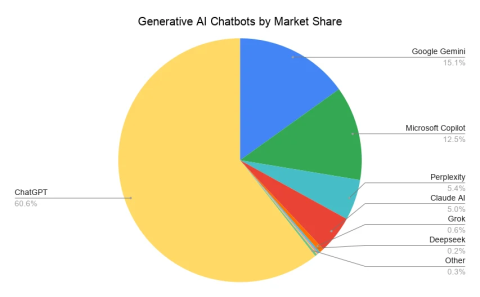
Three names dominate the conversation: ChatGPT, Perplexity, and Gemini. All three are fast. All three are smart. None of that tells you which one will actually convert your buyers.
In First Page Sage's 2026 study of AI referral traffic across 32 industries and 150+ companies, every chatbot tracked converted at higher rates than conventional SEO.
ChatGPT and Perplexity led on average. Claude pulled ahead in knowledge-intensive verticals such as healthcare and higher education.
The three names dominating the space were built for different jobs. That shapes what each one does well, where it falls short, and which buyers it converts. Here's the lay of the land.
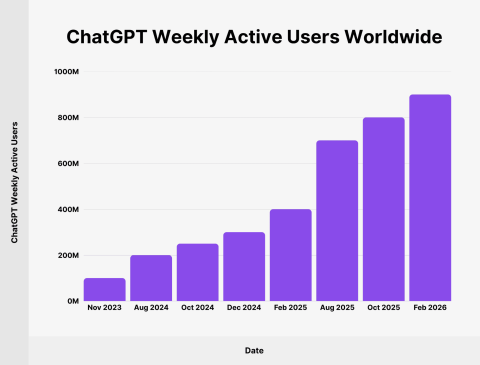
OpenAI shipped the interface that defined the category in late 2022 and has been compounding ever since: custom GPTs, multimodal inputs, and an enterprise stack.
OpenAI reported 100 million weekly active users by November 2023. The current lineup runs from GPT-4o for fast multimodal interaction to ChatGPT Enterprise, which adds data controls and admin tooling.
What it brings to conversions: a chat UX your customers already know, writing and reasoning that hold up under load, and an integration ecosystem deep enough that marketers can spin up workflows in an afternoon.
Verdict: Best for lead generation and purchase intent, conversational qualification, persuasive copy, and fast CRO testing that compounds into real lift across email, chat, and on-site flows.
Built around search-grounded answers with citations. Instead of generating from memory, it retrieves live sources and shows its work.
In conversion contexts where trust and recency are non-negotiable, that's the whole game. Perplexity Pro layers on faster models, file uploads, and enterprise controls.
Gregor Emmian, Deputy Chief Digital Growth Officer at Rise, works in finance environments where trust and information accuracy influence whether users move forward or hesitate.
Emmian says, “In higher-consideration funnels, buyers usually slow down when information feels incomplete or difficult to verify.
Systems that surface sources clearly and reduce uncertainty tend to perform better because they shorten the distance between the question and the decision instead of forcing users to leave the funnel to validate claims themselves.”
Verdict: Great for research-heavy funnels. Use it to cut friction where deals stall, like pricing comparisons, regulated industries, and technical buyers who want proof on the page before they book a call.
Google's family of models is designed for multimodality, long-context reasoning, and ecosystem integration.
Gemini 1.5 brought context windows up to 1 million tokens generally available, with 2 million in private preview, enough to feed it your entire catalog, your full policy manual, or a year of support transcripts without chopping anything up.
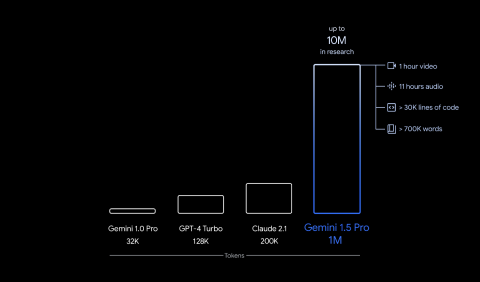
It ties into Google AI Studio, Vertex AI, and Google Cloud, which matters if your team already lives in Workspace, BigQuery, or Google Ads.
Verdict: Best for product discovery in complex catalogs and guided selling, when the buyer's question can only be answered by reasoning across a lot of your own data at once.
Zaheer Dodhia, CEO of Hummingbird International, works with sourcing and manufacturing buyers, comparing specifications, certifications, lead times, and supplier requirements across large product catalogs.
Dodhia says, “Once buyers start comparing technical details across multiple products or suppliers, context loss becomes a real problem. The systems that perform best are usually the ones that can retain the full scope of the conversation instead of forcing users to repeat requirements every few steps.”
Buyers don’t behave consistently across every stage of the funnel. Early-stage users want fast answers, while later-stage users need depth and verification.
The four signals tell you what to measure. The next question is which model wins on which one, and the honest answer is that no single model takes all three rounds.
ChatGPT is the strongest fit when the interaction is short and the goal is clear, such as qualifying a lead on a landing page, handling a support ticket, or walking a buyer through a comparison.
Tone control and few-shot prompting make it the easiest of the three to land on-brand without weeks of prompt engineering. LMSYS's Chatbot Arena consistently ranks OpenAI's top models among the most preferred for helpfulness and reasoning.
Perplexity comes second, but only because its engagement style is narrower.
It earns time on screen through trust, not warmth. Inline citations keep skeptical buyers in the conversation longer. Best fit when the buyer is in research mode, weakest when they want a conversation.
Gemini changes the ranking entirely once the interaction gets long.
For buyers comparing 12 SKUs, support cases spanning weeks, or sales conversations that pick up where the last one left off, Gemini's context window keeps it from losing the thread. Short interactions: ChatGPT. Long ones: Gemini.
ChatGPT is the clearest winner for CRO velocity.
It comes up with loads of headline variants, CTA tests, persona-to-message mapping, and step-level micro-copy, so teams ship more tests faster, and test velocity is where compound gains come from. Custom GPTs let you package what works and reuse it across campaigns.
Jason Ledbetter, Operator at Jason Ledbetter works with marketing and growth systems where testing velocity, operational efficiency, and message consistency directly affect conversion performance.
Ledbetter says, “The advantage with LLM-driven CRO is that testing cycles compress dramatically once messaging, segmentation, and iteration stop, depending on multiple handoffs between teams.
The companies seeing the biggest lift are usually the ones reducing operational drag around experimentation itself.”
Perplexity doesn't compete on test velocity, but beats ChatGPT in one specific scenario: when perceived risk is the conversion blocker.
Cited answers shorten the distance between the question and the decision. In regulated industries or technical B2B, Perplexity outconverts ChatGPT because trust is what's missing, not copy.
Gemini wins CRO only inside the Google ecosystem. Combine Vertex AI Search, BigQuery, and Gemini, and you get context-aware recommendations on-site and in email that ChatGPT can't easily match. Outside that stack, the advantage disappears.
Speed: ChatGPT, narrowly. GPT-4o brought multimodal interaction close to real-time, and the delay between question and answer is where people drop off. Perplexity is slower because it retrieves before it answers. Gemini sits in the middle.
Accuracy: There's no single winner because the failure modes are different:
Usage alone doesn’t guarantee better conversions. Some deployments improve efficiency but not revenue. The strongest results come when AI is tied directly to decision points in the funnel.
Let’s start with how ChatGPT is being used.
Klarna's AI assistant, built with OpenAI, handled 2.3 million conversations in its first month, doing the equivalent work of 700 full-time agents, dropping repeat inquiries 25%, and cutting average resolution time from 11 minutes to under 2, all while customer satisfaction held steady.

But an honest postscript: by early 2025, Klarna rehired human agents for complex and emotional cases where AI quality slipped. The takeaway is that AI clears the tier-1 volume so humans can focus on the messier 20% that actually needs them.
Perplexity Enterprise is emerging in research-intensive B2B workflows.
Gemini's wedge is the data-dense, ecosystem-deep deployment:
The advantage shows up when the assistant has to reason across product catalogs, support docs, and behavioral signals at once, the kind of work that breaks shorter-context models.
Phil Santoro, Co-Founder of Wilbur Labs, works with startup teams to test onboarding flows and operational tooling across multiple portfolio companies simultaneously.
Santoro says, “One of the easiest mistakes with LLM deployments is confusing activity with progress. Teams see longer conversations, higher engagement, or more interactions, and assume the system is working.
But if qualified demos, purchases, or retention don’t improve alongside those metrics, the model is probably creating friction instead of reducing it.”
AI discovery is still poorly measured in most analytics stacks. Many interactions happen before a click or session is recorded. This creates gaps in attribution and makes performance harder to evaluate.
Buyers are asking ChatGPT, Perplexity, and Gemini for recommendations before they ever hit your site, and whether your brand shows up in those answers is a new acquisition channel.
One that doesn’t behave like traditional search, doesn’t measure the same way, and increasingly converts better.
LLMs don't rank pages the way Google does. They surface sources that read as authoritative, well-structured, and clearly attributable.
That means original research, direct quotes from named experts, clean, structured data, and a consistent presence across the web outweigh keyword-stuffed blog posts.
Perplexity, in particular, draws on sites with strong third-party validation, press mentions, reviews, and citations elsewhere, because its model treats them as trust signals.
ChatGPT and Gemini lean on similar patterns when their search layers are active.
The brands recommended are those with tight, consistent messaging across every surface a model might scrape.
Jeffrey Zhou, CEO and Founder of Fig Loans, works in consumer finance, where consistency and explainability heavily affect whether borrowers abandon the process entirely.
Zhou notes, “AI recommendation systems tend to amplify the same trust problems companies already have across search and customer acquisition.
If your messaging changes across review sites, support documentation, landing pages, or third-party coverage, buyers notice it quickly, and increasingly the models do too. Consistency has started functioning like a credibility signal.”
Averages hide important variation within funnels. A model can perform very differently at each stage of the buyer journey. Conversion impact depends more on stage fit than overall industry performance.
The First Page Sage data cited earlier breaks down by 32 industries, and the spread is sharper than the averages suggest.
Hotels & Resorts saw ChatGPT convert at 7.0% and Higher Education at 4.9%, all categories where buyers do heavy research before deciding. Engineering and Transportation lagged at under 2%.
The pattern: high-consideration, trust-heavy verticals see the strongest pull-through from AI referral traffic. Commodity or transactional categories may see less.
Three shifts are already in motion.
There is no universal winner across all funnels. Each model solves a different type of friction in the buying process. The best results come from matching the model to the specific bottleneck.
It depends on your bottleneck.
If you’re evaluating AI tools or implementation partners, third-party credibility matters more now because buyers increasingly validate recommendations across multiple sources before making a decision.
Clutch remains one of the strongest platforms for comparing verified providers, reading client reviews, and understanding how companies actually perform once the engagement starts.

