
How AI Is Reshaping Customer Support
Companies are rapidly adopting AI for customer support, but consumers aren't impressed by chatbots that can't solve their problems. Clutch surveyed 422...
Updated January 26, 2026

AI has become the core of almost every technical operation and product development, but that also makes teams prone to legal pitfalls. To avoid getting caught in that web, you must stay up to date on the regulations governing its use and comply.
AI moved from an interesting demo to an everyday infrastructure quickly. In 2024 and 2025, we saw generative models ship in email, search, design tools, code editors, and call centers. This list continues to grow, and teams are enrolling in courses to stay up-to-date.
But that momentum comes with a clear message for product leaders and engineers. Legal questions concerning your use of AI won’t wait for version 2.0. They show up the day you push to production.
Looking for a Artificial Intelligence agency?
Compare our list of top Artificial Intelligence companies near you
Your customers are not interested in whether you used GPT or Gemini to analyze their financial records. Once they hear about it, their next question becomes, “Who authorized you to feed AI their personal data?”
Regulators, too, have been busy. The EU adopted the AI Act, which includes phased obligations through 2026, setting a baseline for transparency, risks, safety, and accountability across the market. In the U.S., agencies have issued targeted guidance and enforcement signals, while states like Colorado have passed laws that will take effect in 2026 for high‑risk AI.
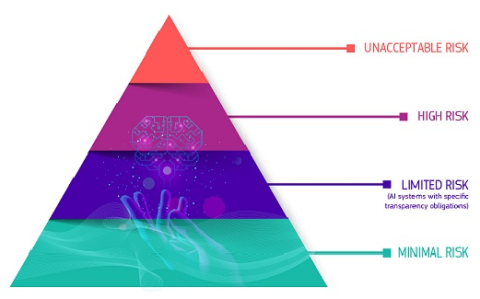
Source: DigitalEuropa
Therefore, if you plan to ship AI in 2026 for any reason, it is essential to stay informed and compliant to avoid potential legal complications. In this article, we’ll discuss how to do that.
The risks you face fall into two big buckets:
These outcomes are highly likely and usually result from the following.
Models can memorize sensitive data if training or retrieval isn't carefully constrained. Using personal data without a proper legal basis, ignoring opt-outs, or mishandling data subject requests can trigger penalties under the GDPR and state privacy laws, such as California's CCPA/CPRA.
Automated decisions that significantly affect people also raise special obligations under GDPR Article 22.

Teams must decide when an AI system stops assisting and starts deciding. At that point, the law requires transparency, human oversight, and clear explanations. These are legal duties, not optional safeguards.
These create the second major risk area. Hiring, lending, housing, insurance, and healthcare are magnets for regulatory attention. U.S. regulators have warned that Title VII, the Fair Credit Reporting Act, ECOA, and UDAP laws still apply when algorithms are doing the sorting.
The EEOC has also issued technical assistance on the use of AI in employment decisions, and New York City requires bias audits for automated employment decision tools. Additionally, the CFPB has flagged black box credit models that can't explain adverse decisions. These regulations aim to eliminate or minimize discrimination and bias in AI use.
Both round out the major concerns. Risks associated with prompt injection, data poisoning, and model output, such as defamation, medical or financial misinformation, and safety bypasses, aren't theoretical. That’s why red-teaming and robust guardrails matter, and proactively, not as an afterthought.
Kos Chekanov, CEO at Artkai, who leads product teams building customer-centric technology where safety is engineered into workflows, reiterates this point with his experience.
“Teams get into trouble when safety is bolted on at the end. If AI is part of your product logic, treat guardrails like any other core feature. Define failure states, add human checkpoints for sensitive outputs, and log decisions from day one so audits are routine, not reactive”, Kos says.
Early guardrails lower legal and operational risk. Logging decisions, enabling explanations, adding human review make audits and investigations easier to manage.
While not a major, it still adds another layer.
According to Brandy Hastings, SEO Strategist at SmartSites, provenance is becoming a credibility and ranking signal that affects you directly.
“Search platforms now evaluate whether your content is traceable, labeled, and attributable. But when your outputs lack these, you introduce ambiguity that algorithms and regulators are more likely to penalize than overlook.”
This is especially crucial as Generative AI providers and platforms pilot watermarking and provenance standards, such as C2PA.
We're already seeing real-world lessons. For instance, New York City's AEDT law forced hiring teams to inventory tools and run bias audits. Media companies filed high-profile copyright suits related to training and outputs, including The New York Times' complaint against Perplexity in late 2025.
Anthropic had to pay out over $1.5 billion to compensate book authors in the same year, dubbed the largest copyright settlement payout since AI’s inception. Interestingly, this precedent could lead to higher figures in the future as lawsuits continue to rise, and some lawsuits seek to recognize generative AI content as defamatory.

The FTC is not relenting either. The regulatory body clarified it could hold companies responsible for legal breach if they fail to disclose how data is managed to customers, so long as it influences purchasing decisions.
The thing is, these patterns will get more detailed in 2026, and the legal guardrails might become more distinct and less possible to circumvent, in case you plan to.
Intellectual property sets the rules for who can use, share, and profit from creations. But with AI, those rules meet some new wrinkles. Let’s break them down.
In the U.S., the Copyright Office makes it clear that works created without human authorship aren't protected. Human selection, arrangement, or sufficient creative control can be protected, but purely machine-generated output cannot be registered as-is.
Courts have reinforced this, including a 2023 decision holding that an AI system can't be listed as an author for copyright registration. Any copy must be human-led before it can hold the authorship label.
This remains unsettled in the U.S., with several cases ongoing. In the EU, text and data mining (TDM) exceptions exist for research and, with opt-out, for broader use under the EU DSM Directive.
Providers are also moving toward more transparency about training data summaries in Europe under the AI Act. Therefore, it is essential to be aware of the local laws in your region of residence and service to understand what’s permitted and what’s not.
Both vary by tool. Terms often grant you broad rights to use outputs, but there may be restrictions, for example, on generating sensitive content or reverse engineering.
Some providers now offer IP indemnity for enterprise use cases, such as Microsoft's Copilot Copyright Commitment and Google's indemnification for certain generative AI products.
These licences add complexity. For instance, popular models come with custom licenses, like Meta's Llama Community License or OpenRAIL for some diffusion models. These aren't standard open-source software licenses and may impose use restrictions and distribution limits.
Before usage, read them like you would a contract, because they are, and document your creative process and your use of AI if any legal issue arises in the future.
Generative AI is integral to the modern workflow. Rather than snuffing it out to avoid regulatory guardrails, here's a practical approach to ship it with confidence.
The steps below outline a practical framework for implementing generative AI in 2026, while meeting legal and regulatory expectations.
Joern Meissner, Founder of Manhattan Review, builds learning systems in which mastering complexity begins with disciplined mapping and an understanding of fundamentals.
He advises, “Treating your AI legal checklist like a curriculum. First, define what counts as compliance success, then structure your steps so every stakeholder knows what to document and why. From there, describe the user journey, data flows, and model decisions.”
Additionally, call out any decisions that significantly affect a person, such as credit, employment, housing, health, and safety. Identify jurisdictions where users or data reside to scope which laws apply.
Screen for high-risk categories under the EU AI Act and similar state laws. If you're in hiring, lending, or critical services, plan for impact assessments and extra documentation. Decide whether your model is general-purpose, fine-tuned, or task-specific, and whether you're a provider or deployer under EU definitions.
Compare hosted APIs vs. self-hosted or open models. Hosted solutions can reduce operational burden but increase vendor dependencies. Treat the terms of service as a product requirement.
Also, confirm training rights, data retention policies, fine-tuning data usage, output ownership, rate limits, indemnity, and any restrictions for sensitive uses.
Apply data minimization and purpose limitation. Avoid sending personal data to third parties unless necessary and documented. Use separate and encrypted channels for secret keys and PII. Consider zero-retention modes where available. If GDPR applies, complete a Data Protection Impact Assessment and verify appropriate transfer mechanisms.
Add input validation, prompt hardening, and context filtering. Layer content filters and retrieval guardrails. Log prompts and outputs for auditability. Red-team against your risk scenarios like hallucination, defamation, harmful instructions, and bias.
Define metrics aligned with your domain, such as fairness across protected classes, false positive and negative rates, and calibration. Then run pre-deployment and ongoing bias testing, and document datasets, configurations, and results.
Tyler Denk, Co-founder and CEO at beehiiv, runs a platform that relies on clear communication to build loyalty and trust with a user base.
And he says, “The fastest way to lose trust is to hide automation behind vague language. If users are affected by an AI decision, they deserve to know it upfront. Provide clear user disclosures when AI is used, how outputs are generated, and any material limitations, as indicated by GDPR and other guiding laws.”
Offer human review or appeal pathways for impactful decisions. Also mention which AI tools are involved and non-AI actors, such as data partners and third-party tools.
Maintain model cards or system cards summarizing data sources, intended use, known limitations, and evaluation results. NIST AI RMF and the draft Generative AI Profile offer a helpful structure you can implement. For the EU, prepare the technical documentation required under the AI Act, including logs and training data summaries for GPAI, as applicable.
Set thresholds that trigger rollback or human review. Establish a process to address user rights requests and rectify harmful outputs. Make sure your AI claims are truthful and substantiated, including accuracy rates and capabilities FTC guidance.
By 2026, EU AI Act obligations are likely to phase in strongly. High-risk systems will undergo conformity assessments, providers of general-purpose AI will face transparency and documentation requirements, and users will see increased labeling of synthetic media, as stated in the EU AI Act.
You should also expect the U.S. patchwork to tighten, while state-level rules to expand beyond privacy to include algorithmic accountability. Colorado's law is an example, and employment-focused audit requirements will continue to spread.
Federal agencies may continue to use existing law for enforcement, guided by the policy direction outlined in the 2023 Executive Order. And mandatory auditing and transparency will gain traction.
More clarity on IP will also emerge. Courts and regulators will refine the boundaries of fair use for training, obligations to respect TDM opt-outs in the EU, and what counts as sufficient human authorship.
Lastly, do you know the limitations of the Canva free model? Watermarks. You should now anticipate the same level of adoption for AI use. Watermarking for synthetic media, nudged by major platforms and policy guidance, could become the norm.
Legal work can feel like friction, but in AI, it works more like a design constraint that forces better decisions. To avoid getting on the wrong side of your customers and the law, start by building privacy and fairness into your business practices.
Read your licenses like your business depends on them, because it does. Use common frameworks to align teams and speed audits. And stay informed about local rules governing your operations and global regulations as needed.
Document your decisions, test your systems, and stay adaptable to avoid headlines and earn trust.

