
How App Companies Can Build Trust with Customers
Learn how app companies can build customer trust through better privacy practices, transparent communication, and stronger security to improve retention and...
Updated April 7, 2026

A practical roadmap for building AI apps that work outside of demos, covering data, system design, testing, and scaling under real-world conditions.
AI in 2026 isn't experimental anymore.
You see it in how companies are actually using it. Factory defects are caught earlier. SaaS search feels smarter. Support teams handle far more volume without hiring at the same rate.
Looking for a Mobile App Development agency?
Compare our list of top Mobile App Development companies near you
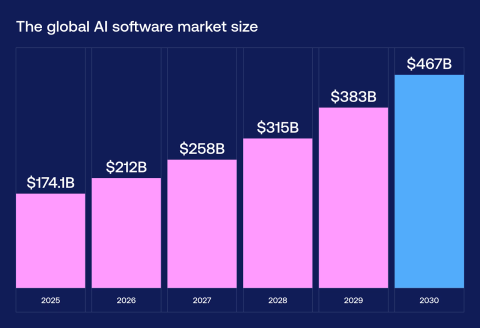
McKinsey’s State of AI research reflects this shift: less hype, more focus on measurable business impact.
This guide walks through how to build something real in this environment, something that survives production, not just a demo.
There’s no shortage of tools. That may be a problem; there are so many that it’s hard to decide what’s right for you.
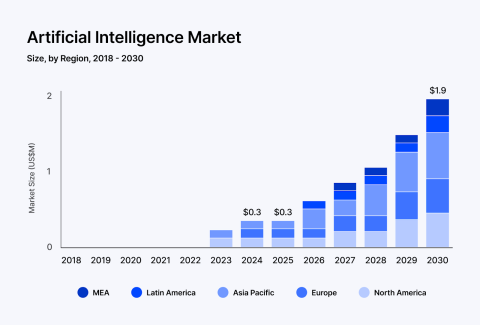
Pick the right ones early so you don’t have to rebuild everything later.
All of this is good, but it creates a trap.
Cloud providers will happily give you everything end-to-end. It’s fast. It works. And it locks you in before you realize it.
The decisions you make here stick. You’ll feel them when you try to scale, switch vendors, or reduce cost.
Don’t start with what AI can do; instead, focus on what needs to be solved.
You need a sharp problem. One where improving the outcome by 10x actually matters.
Talk to users. Sit with them while they work. Watch where they slow down, where they double-check, where they hesitate. That’s where the opportunity is.
Then define the role of AI clearly.
Is it predicting something? Summarizing? Retrieving? Generating? Automating actions?
Pick one. Keep the first version tight.
Generic AI tools are already becoming infrastructure. The apps that stand out are the ones that solve very specific problems for very specific people.
Your app isn't just a model. It's a data engine, a set of services, and a user experience that hides the complexity.
Modern AI systems increasingly interact with physical infrastructure.
In logistics and manufacturing, machine learning models are used to optimize inventory placement, predict demand, and guide picking workflows. These systems often integrate with automated storage solutions like a vertical lift module, which delivers items directly to operators and improves both speed and accuracy in warehouse environments.
You’ve got:
Where things usually break is the interface between AI and UX.
Users don’t care about your pipeline. They don’t care about confidence scores or embeddings.
They care if the output is useful.
So you hide the mess. You surface only what helps them decide or act.
If you’re integrating with other systems, define contracts early. Data lineage and permissions matter more than people expect, especially once multiple teams get involved.
Leon Huang, CEO of RapidDirect, works closely with teams building AI-assisted manufacturing systems, where even small integration gaps result in immediate production delays.
He says, “Most teams focus on getting the model output right, but the real work starts after that. You need clean handoffs into quoting systems, design validation, and production constraints. The teams that get this right define their data formats and integration points early, so the AI output can move straight into execution without manual correction.”
And if you’re building a RAG system, map the flow end-to-end. Source → chunking → embeddings → index → retrieval → prompt → generation → post-processing → safety.
Miss one step, and you’ll spend weeks debugging something that looks like the model is wrong.
Start with a simple truth: the model is rarely the problem.
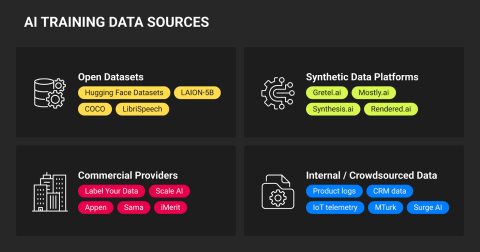
Data is.
You can pull data from public datasets such as Kaggle, Hugging Face, Common Crawl, and LAION. These are large, pre-collected datasets used for training and benchmarking. Great for getting started and for prototyping.
But they don’t reflect your users.
And volume isn’t the advantage people assume it is. The DataComp study showed that better curation consistently outperforms larger datasets.
You see this quickly in production.
Clean, structured data gives you outputs you can trust. Messy data gives you answers that sound right but aren’t.
If you want something that actually holds up, you need closer-to-source data.
That’s where partnership data comes in.
Partnership data is data you get through direct relationships with customers, vendors, or internal teams. Think support tickets, chat logs, transaction records, and operational workflows. This is data generated as a byproduct of real work.
It’s usually smaller than public datasets. But far more relevant.
It shows how people actually behave, where they struggle, and what edge cases look like in the real world.
But you don’t get it for free.
You need contracts. Clear permissions. Defined usage boundaries. And often, anonymization before you can even touch it.
Then there’s synthetic data.
This is artificially generated data designed to mimic real-world patterns, often used to fill gaps, test edge cases, or avoid handling sensitive information directly.
But it’s not a shortcut. It still needs validation against real data, or you risk training on something that looks realistic but behaves differently in production.
This is where most teams lose discipline.
Deduplicate, normalize, and define schemas early. Label with intent, not guesswork. And document it properly.

When something breaks, and it will, you need to trace it back. Where the data came from. How it was transformed. What assumptions were made.
Model cards and dataset documentation make that possible.
Privacy sits across all of this. Design it from the start.
If you’re handling sensitive data, frameworks like GDPR, the EU AI Act, and the NIST AI RMF aren’t optional anymore. They shape how you collect, store, and use data.
Teams that treat this as a checkbox usually end up rebuilding once they scale. And by then, it’s expensive.
There’s a tendency to overcomplicate this.
Transfer learning and adapters save time. Federated learning helps when data can’t leave devices.
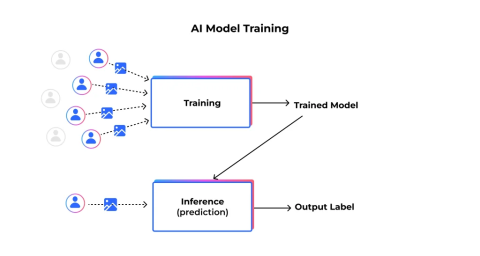
But again, fit the approach to the problem. Not the other way around.
Offline evaluation helps; it’s testing your model on a fixed dataset before users ever see it. But it won’t tell you how the system behaves in real-world use.
You need to test how it fails. Which users does it fail for? What edge cases does it collapse on?
You don’t see the real issues until you’re running live. On paper, everything looks fine. But once you’re actually moving, crews, trucks, timing, you start noticing where things fall apart. The only way to fix it is to watch those failures closely and adjust based on what’s actually happening.
Slice performance by segment, new users vs power users, clean inputs vs messy ones, not just averages. Because averages hide the problems that actually matter.
For LLM-based systems, this gets sharper.
Red teaming isn’t optional. That means deliberately trying to break your system, feeding it malicious prompts, misleading inputs, or edge cases to see how it responds.
Then there’s latency.
Latency is the time it takes your system to respond. And users feel it immediately. A response that takes too long (even if it’s correct) feels broken. So you have to measure it properly.
Once you move to deployment, the goal shifts.
Feature flags let you turn features on or off without redeploying. Canary releases let you roll out changes to a small percentage of users first, to see if anything breaks. Rollbacks let you quickly revert when something goes wrong.
And then you’re live.
This is where the real work starts.
You’re watching for drift: when incoming data starts to differ from what the model was trained on, causing performance to degrade. You monitor for performance drops, safety issues, and cost spikes that creep in over time.
And you need feedback loops because there’s always a gap between outputs that are technically correct and outputs that are actually useful. Human feedback helps close that gap.
Rawad Baroud, CEO of ZeroGPT, focuses on helping teams evaluate and maintain trust in AI-generated content as it scales across real workflows.
He says, “Getting an output that looks correct isn’t enough. Teams need a way to verify whether it actually holds up, whether it’s original, consistent with their standards, and safe to use. The most effective setups introduce validation layers early, so issues are caught before the content reaches users.”
Through all this, A/B testing will keep you honest. Show different versions of your system (different models, prompts, or UX flows) to different groups of users and measure which one performs better. You don’t rely on intuition.
You’ll run into the same problems most teams do.
Privacy and security are major concerns here. Minimize data, encrypt everything, and define retention clearly.
This also extends to how agreements, permissions, and retention policies are tracked internally. As systems scale, teams need structured ways to manage obligations and access controls, often through tools like contract management software, so compliance doesn’t rely on manual oversight.
Some other challenges are:
The teams that get through this expect problems and design around them.
A few shifts are already visible.
On-device models are getting strong enough to handle real workloads. That changes latency and privacy expectations.
Agents are improving, but only when constrained. Open-ended systems still fail unpredictably.
Data provenance is becoming required, not optional. Standards like C2PA are moving in that direction.

And regulation is now part of product design. Not legal cleanup.
Teams that understand their domain deeply. and build tightly integrated systems, will outperform general-purpose tools.
Building an AI app now is less about chasing capability and more about making disciplined decisions.
The gap between a working prototype and a reliable system usually comes down to execution. Clutch helps you evaluate partners based on verified client reviews and real project outcomes, so you’re not relying on claims but on proven delivery.

