
Chatbot Best Practices: 7 Tips for Better Customer Support
Learn seven chatbot best practices to improve customer support, reduce frustration, and create faster, more helpful AI-powered customer experiences.
Updated May 12, 2026

Adding AI is the milestone people see. Keeping it stable and usable after launch is where most of the work actually happens.
Adding AI to a product is rarely where things get difficult.
You can get a model working, connect it to an interface, and ship something that looks impressive in a demo or even in early usage.
Looking for a Artificial Intelligence agency?
Compare our list of top Artificial Intelligence companies near you
The shift happens once it’s live long enough, when traffic increases, and inputs stop looking like your training data. Edge cases stop being rare.
And suddenly, the system you thought was good enough starts behaving inconsistently, making it hard to debug and even harder to explain to users.
Most teams think they have a data problem. What they actually have is a data reliability problem.
At the start, it looks manageable: pull logs, label data, and train a model. But once you get into it, you start seeing how inconsistent everything is.
A model works well across 80% of cases. Then the remaining 20% shows up repeatedly in production, as patterns you never captured.

Phil Santoro, Co-Founder at Wilbur Labs, works on building and scaling startups with durable value — which gets harder when core parts of the product depend on systems the team doesn’t own.
Santoro says, “You’re now dependent on a model you don’t own. The provider deprecates a version, changes pricing, tightens a safety filter — and your product behavior changes overnight without you touching a line of code. Most teams build like the model is a stable dependency. It isn’t.”
This is why data preparation ends up taking the majority of the timeline. Every shortcut shows up later as a failure mode.
Scaling laws help explain why adding more data improves performance, but that only holds when the data actually represents what the model needs to learn. If it doesn’t, you just get more confident mistakes.
Infrastructure tends to lag behind this.
Pipelines that work in staging start failing under real load. Feature mismatches appear between training and inference. Retraining becomes risky because you can’t guarantee consistency across runs.
At that point, you have to stop chasing small accuracy gains and start trying to make the system predictable.
The model you choose early on rarely survives unchanged.
On paper, it makes sense to pick the highest-performing option. In practice, that model is often too slow, too expensive, or too sensitive to small variations in input.
So step back.
Look at latency budgets, how often the model will be called, and how incorrect outputs affect the user experience. A slightly worse model that behaves consistently is usually the better choice.
Christopher Skoropada, CEO of Appsvio, works on SaaS products where AI features need to function inside live user workflows rather than controlled environments.
Skoropada says, “We’ve tested models that looked great on benchmarks but created friction once users started interacting with them repeatedly. Small inconsistencies add up fast. We now prioritize models that behave predictably across edge cases, even if the raw performance is slightly lower.”
This is where evaluation changes.
Accuracy stops being the only metric that matters. You start caring about specific failure modes. False positives in some systems are far more damaging than false negatives. In others, it’s the opposite. Sometimes, latency matters more than either.
Once you start customizing (fine-tuning, adding domain-specific logic), you’re no longer just using a model. You’re maintaining one.
That brings its own overhead. Training pipelines, evaluation that reflects real inputs, and constant checking for edge cases that didn’t exist when you started.
This is where most of the unexpected work sits.
AI systems are inserted into existing architectures that already have constraints, such as fixed schemas, strict response times, and compliance requirements that don’t allow for flexibility.
You end up writing a lot of glue code.
None of this is complicated individually, but together it becomes a system you have to maintain alongside the model.
Gavin Yi, CEO and Founder of Yijin Solution, works with manufacturing clients where systems have to align with strict technical specifications before anything moves forward.
Yi says, “In manufacturing workflows, outputs have to match exact requirements, or they’re not usable. When we introduced AI-driven processes, the challenge wasn’t generating results, it was making sure those results could fit into existing systems without creating rework or delays.”
The issues are usually small, but persistent.
A field that isn’t populated consistently, or a feature that exists in training but not in real-time inference. Maybe a service that behaves differently under load than it did in testing.
Feature stores help with alignment, but they don’t fix upstream inconsistency. If the source data isn’t stable, the model won’t be either.
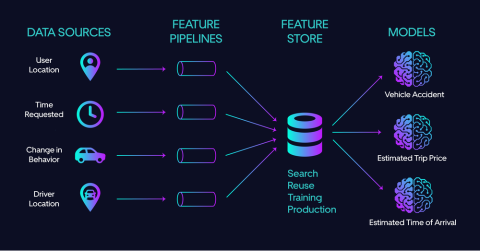
And while all of this is happening, the user experience is still exposed to it. Delays, inconsistent outputs, or confusing behavior quickly erode trust.
Once the system is live, it doesn’t stay still.
User behavior changes. New inputs show up. The assumptions you trained the model on start drifting.
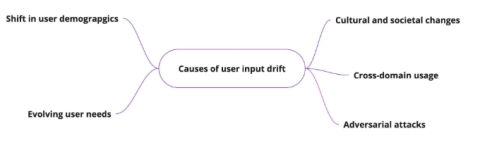
At first, the changes are easy to miss, slight drops in performance, weaker outputs in certain segments. Over time, they become consistent enough to notice.
At that point, the question isn’t whether performance has changed, but why.
That means looking beyond a single metric. Teams track input distributions, latency, output confidence, and business metrics tied to the feature. It often takes multiple signals to understand what’s shifting, because no single metric captures the full picture.
Fixing issues is more involved.
It requires retraining pipelines to produce consistent results, evaluating against both historical data and live traffic, and implementing rollback mechanisms when changes underperform.
Updates often affect specific segments rather than the entire system, which makes them harder to catch early.
Over time, maintaining the model becomes an ongoing part of operating the system, not something handled at set intervals.
Adrian Iorga, Founder and President of Stairhopper Movers, runs a logistics operation where conditions shift constantly across routes, timing, and demand.
Iorga says, “In operations, nothing stays consistent for long. Volumes change, constraints change, and small inefficiencies show up quickly. Any system tied to that environment has to be monitored and adjusted consistently, otherwise it starts creating problems instead of solving them.”
AI systems introduce failure modes that don’t exist in traditional systems.
Inputs can be manipulated in ways that look normal but produce incorrect outputs. Adversarial examples are a well-documented case of this (Goodfellow et al., 2014), but the broader issue is that models can be sensitive to patterns that aren’t obvious.
There’s also the risk of unintended data exposure.
Models that overfit or memorize parts of their training data can leak information through their outputs. Techniques like membership inference and model inversion have shown that this is not just theoretical.
Addressing this means expanding your security approach, validating inputs, monitoring outputs for anomalies, and reducing the likelihood that sensitive data is embedded in the model in the first place.
And this evolves. As the system changes, so do the risks.
Once the model influences decisions, expectations change.
You’re no longer just building a feature. You’re responsible for how that feature behaves across different users and scenarios.
That’s where documentation starts to matter more.
Model Cards and Datasheets for Datasets are not just formalities; they are ways to make explicit what the model does well, where it struggles, and what assumptions it relies on.
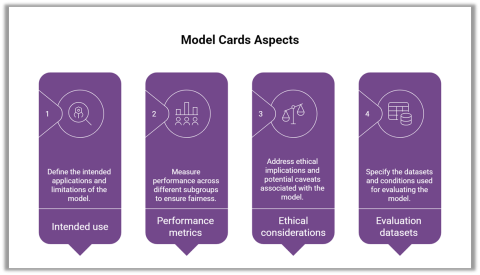
Regulation is moving in the same direction. Frameworks like the NIST AI Risk Management Framework and the EU AI Act are pushing toward clearer accountability, especially in higher-risk applications.
In practice, this means keeping track of decisions you might not have documented before, data sources, model changes, and evaluation criteria.
It adds overhead, but without it, systems become harder to defend internally and externally.
Even if the system works technically, adoption isn’t guaranteed.
Users don’t evaluate models the way teams do. They don’t care about accuracy percentages. When a system stops helping them reliably in the moments they use it, they stop using it.
Wade O’Shea, Founder of BusCharter.com.au, works with users coordinating transport under time pressure, often comparing options quickly before making a decision.
O’Shea says, “Most users aren’t thinking about how the system works. They’re trying to get a result quickly and move on. If the experience adds extra steps or behaves unpredictably, they switch to something simpler, even if it means doing more work manually.”
What works better is introducing AI features in a way that gives users early, consistent wins. Not everything at once, and not in a way that requires them to understand how the system works internally.
Feedback loops help, but only if they lead to visible changes. Otherwise, they become noise.
Transparency also matters, but it has to be practical. Confidence indicators or simple explanations can help, but only if they actually clarify what’s happening.
The pattern is consistent across teams. The model is not the hard part for long. The surrounding system becomes the work: data quality, infrastructure, integration, monitoring, security, and user trust.
These can degrade gradually.
And that’s usually how AI features lose momentum, when they stop being reliable enough to depend on.
If you’re evaluating vendors or planning to bring AI into an existing product, it helps to see how others have handled similar constraints.

