
How to Vet a Software Development Agency in 2026: 8 Signals That Actually Predict Project Success
Does the agency live up to its proposal? These eight signals help you tell the difference before you sign anything.
Updated June 15, 2026

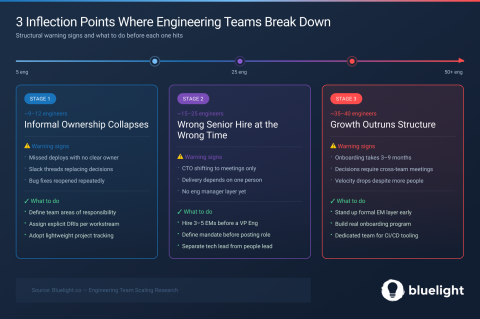
Growing an engineering team is rarely a headcount problem. It usually is a structural problem. Here are the three inflection points where most SaaS engineering organizations quietly break down, and what to do before each one hits.
Some teams believe that when delivery slows down, sprints aren't moving things forward, and bugs are slipping through, the fix is to hire more engineers. A couple of months later, they will probably be shipping less than you did with fewer engineers: same codebase, twice the people, half the velocity.
If you want to fix the real problem, focus on how your team's structure is working, rather than adding headcount unless necessary. What you should do first is to define areas of responsibility. Focusing on this will help the team spend more time building projects rather than coordinating.
Looking for a Software Development agency?
Compare our list of top Software Development companies near you
Fred Brooks, in his book The Mythical Man-Month, showed that communication overhead in a team grows exponentially as you add people. A team of 10 has 45 possible coordination channels. A team of 50 has 1,225. Nobody ships fast code through 1,225 conversations. Before asking how many engineers you need to add to your team, ask yourself: What structure does your team need before adding anyone else?
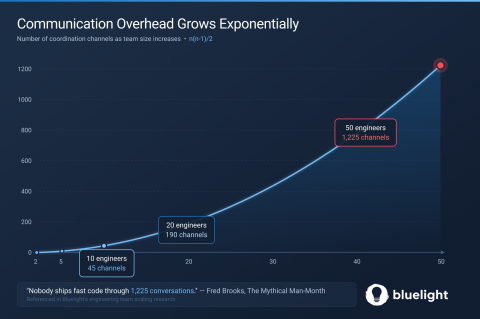
In an early-stage engineering team, everyone knows what everyone else is working on. Ownership is informal; there are no real systems set in place, and decisions happen in Slack threads. With six or seven engineers, it works fine. Around nine or ten, you start noticing the cracks. When you reach a team of 12, communication and coordination usually break down. By then, it usually hasn’t been diagnosed yet.
There’s a theory, Dunbar’s number, that suggests humans can maintain genuine relationships with only a limited number of people. This happens not only at the social level but also within organizations. Trying to coordinate too many people eventually undermines the quality of their work. Past a certain threshold, individual accountability begins to weaken, causing collective results to fall below what the headcount should produce.
In this scenario, project ownership is what begins to break down. When nobody can say who’s responsible for the pipeline’s deployment, it is because the structure that worked at the beginning, with two engineers, is now falling apart. When you have a team with cross-team dependencies, informal coordination and communication won’t be enough. You need to see far beyond the code quality and start focusing on organizational systems.
Fixing it is simple if you act before the problems force you.
Once ownership is formalized and the team structure holds, the next temptation is to accelerate growth by bringing in a more senior hire, and that's where a different set of problems begins.
The second trap when scaling your team is trying to fix the previous stage by bringing in a more senior staff engineer. Hiring for this type of role usually becomes more expensive because it involves a larger role. Failures are frequently attributed to the new role, when the root cause is typically the organization's own architecture. This leads to a contextual mismatch, but it is often confused with personal incompetence. It's more common for the organization to fail to integrate the hire than for the hire to fail to deliver.
A senior engineer joins a well-funded company and can’t figure out how the systems connect or what their role covers; this is a pattern. Not because they weren’t good enough, but because nobody had built the systems they needed to operate.
The premature VP of Engineering hire is the most expensive version of this. A well-documented pattern in engineering leadership shows that companies often let go of their VPE within the first quarter after hiring, not because of individual failure, but because they hired a technical depth leader when what the organization needed was a people-scaling leader. A right fit is partly a function of timing; only hire a VPE when you have three to five Engineering Managers already running. Without that layer, the role has nowhere to go.
Fix this by doing the following before hiring any senior role:
Even when the right people are in the right roles, scaling past 25 engineers introduces a new layer of complexity, one where the structure itself starts working against delivery.
Stage 3 is the sneakiest because the symptoms look like execution failures. Delivery is slowing despite everyone working hard. Onboarding takes way longer than expected. Decisions that used to happen in one Slack thread now require a meeting, which in turn requires another meeting.
Consistently, at this scale, the slowdown isn't an execution problem; it's a structural one that somebody deferred. Unstable organizational priorities lead to productivity declines that persist even with strong leaders and good documentation or systems. This usually means the Stage 1 structure was never replaced, even as the team grew.
A useful rule of thumb for team sizing: You should consider having 6 to 8 engineers per manager, not more. When you have a team of 35 or 40 and don’t have a proper manager layer, everyone slows down delivery, and most of the time, you can’t find out why.
Onboarding also breaks at this scale. Getting a new engineer to full productivity takes 3 to 9 months, depending on the codebase's complexity and the quality of the documentation. The teams that invest in this before the pain arrives scale cleanly — Stripe’s approach, with over 30 sessions and 82 dedicated instructors, is a useful benchmark for what serious onboarding looks like. Stand up a formal EM layer early, build a real onboarding program, and create a platform team to own shared tooling and CI/CD. At 40 engineers, these are load-bearing.
Recognizing which stage a team is in is only half the problem, the other half is knowing which hire to make next, and in what order.
You shouldn’t treat all engineering hiring decisions the same way. A backend engineer and a VP of Engineering are both “hires” and are most of the time evaluated roughly the same way. The order in which you add roles to your team matters more than most people know. Hire the wrong person at the wrong time, and it can cost you performance.
Priority, before adding more individual contributors: technical coherence. You need someone whose job it is to understand how the systems connect, make architecture decisions without everything routing through the founding CTO, and bring new hires up to speed. This is usually an internal promotion. If it’s external, it’s your top priority.
Bring in your first engineering manager when people management is eating more than 30% of your tech lead’s time. An EM’s job isn’t to be the most senior technical person in the room — it’s career development, performance conversations, and cross-team coordination so technical leads can stay technical. These are genuinely different skill sets.
Hiring a VP of Engineering too early is the most common mistake in engineering scale. A VPE adds real value when there’s a manager-of-managers problem to solve — when your span of EMs is getting unwieldy, or the founding CTO needs to shift from people management to technical strategy. Bring them in before three EMs are running, and the role has no real leverage. Regarding a dedicated QA lead, it is important to note that this role is effective only when the product is stable enough to support a structured testing strategy. Attempting to hire for this position during a period of instability will prevent the role from becoming established.
Warning signs that your team is broken go unrecognized early enough, since most engineering leaders focus on revenue, feature velocity, bug counts, and other lagging indicators. It doesn’t mean you shouldn’t be tracking this, but those are numbers that tell you about a problem that’s already fully formed.
Cycle time is a useful indicator. If the average time from ticket start to deployment is increasing exponentially over six to eight weeks with no architectural reason, work is piling up somewhere. That’s a coordination problem, not a speed problem.
Deployment frequency is another indicator. If it’s quietly declining quarter over quarter without a deliberate reason, that’s a structural signal. Most teams know the benchmarks that state that elite engineering teams deploy on demand with change lead times under a day, but are unable to connect declining deployment frequency to the structural issues that cause it.
Teams also fail to notice when PR review queues grow, mostly because code ownership hasn’t been formally assigned. Onboarding health can be determined by how long it takes a new hire to make their first meaningful commitment. It could be days in well-structured teams, three to four weeks in teams with weak or no documentation or systems.
For companies with a core product area that needs long-term ownership or a technical direction that requires someone embedded in the culture for years, these gaps call for a permanent hire. Not every gap fits that shape. Some are time-bound, domain-specific, and urgent, and full-time hiring is a slow, heavy way to solve them.
A clear example of this is teams that need to accelerate their product launches, close skill gaps, or increase QA capacity. When companies try to hire full-time senior software engineers in the US, the process takes an average of 90 days. These hires cost more than $4.6k before the three- to six-month ramp-up. That doesn’t work when you’re trying to launch a time-bound project.
Sometimes, the best way to close gaps in teams is through nearshore team augmentation. It helps solve this by providing pre-vetted engineers who’ve already cleared technical screening and can join your team within weeks. The good thing is you don’t need a permanent headcount, nor long-term overhead, just a scoped contributor for as long as the work requires. Team augmentation helps close specific gaps and deliver clear outcomes without requiring any reorganization.
Most engineering leaders look at their organization chart as if it describes the team as it operates today. What it actually shows is the last structural decision that got made, which is usually after something broke. Your next delivery crisis is probably already baked into the structure you’re running right now.
The three stages shared at the beginning of this article aren’t unusual or unpredictable. The only real variable is whether you recognize what’s happening in time to act before it is too late.
You will know when to make structural changes before they become delivery failures by monitoring cycle time, deployment frequency, PR queue health, and onboarding ramp time.
What the teams that scale well have in common is remarkably consistent. They’re not always the ones with the most capital or the most recognizable engineers. They’re the ones where someone in a leadership seat recognized early that building an organization is a different job than growing a group of people who write code.

