
Customer Expectations in AI Support: What Businesses Need to Run it Smoothly
Consumers increasingly expect AI-powered customer support. Here's what customers want, and what it takes on the backend to deliver it.
Updated May 28, 2026

Cloud cost optimization is the practice of reducing unnecessary cloud expenses while keeping infrastructure performance and scalability intact. It goes beyond basic cost management by aligning spending with business priorities and ensuring that resources are right-sized, governed, and continuously monitored.
The need has never been greater. Flexera’s State of the Cloud Report 2025 found that 33% of companies now spend more than $12 million annually on cloud, yet 84% still cite cost management as their top challenge. HashiCorp’s 2025 Cloud Complexity Report echoes the problem: 98% of organizations face cost challenges tied to complex, multi-cloud environments. With budgets under pressure and cloud powering more critical workloads than ever, companies that fail to optimize may either overspend on unused resources or cut too deeply and compromise performance.
To optimize cloud spending, businesses need to start with visibility into what drives their bills. The biggest categories are compute, storage, networking, and managed services — and inefficiencies in any of them can drain budgets quickly.
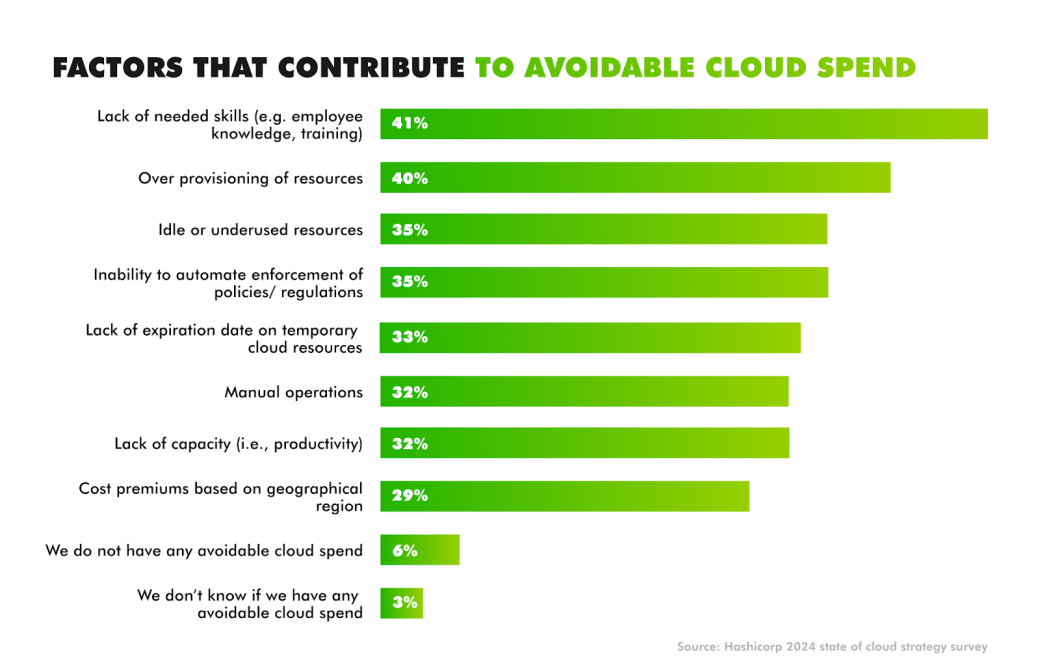
Compute is often the largest line item. Idle or oversized virtual machines, abandoned test environments, and workloads left running outside business hours all contribute to waste. Flexera’s State of the Cloud Report 2025 found that companies estimate 28% of their cloud spend is wasted, a figure that has remained stubbornly high even with the rise of automation platforms.
Storage brings hidden costs of its own. Orphaned volumes tied to terminated instances, snapshots kept far beyond retention policies, and storing rarely accessed data in premium tiers all inflate bills. Without lifecycle policies, storage quickly grows into one of the hardest areas to keep under control.
Networking and managed services add complexity. Data transfer fees, especially across regions or out of the cloud entirely, can be unpredictable and expensive. Managed services such as databases, analytics, and AI platforms deliver speed and scalability but are often overprovisioned or under-monitored. According to HashiCorp’s 2025 Cloud Complexity Report, nearly every organization reports rising costs tied to managing multi-cloud services, with cost visibility cited as a core governance challenge.
The bottom line: cost overruns are less about isolated missteps and more about systemic inefficiencies across compute, storage, networking, and services. Understanding these drivers is the first step toward a cost optimization strategy that reduces waste without cutting into performance.
Cloud cost management refers to tracking, monitoring, and controlling expenses — reporting what was spent, on which services, and by which teams. Cloud cost optimization goes even further, as an ongoing process of refining workloads, rightsizing resources, and enforcing governance so that cloud investments deliver the best possible performance for the money spent.
The distinction matters because waste remains high. Flexera’s State of the Cloud Report 2025 found that 28% of cloud budgets are wasted on average. HashiCorp’s 2025 Cloud Complexity Report shows that 98% of organizations face cost challenges in multi-cloud environments, where poor visibility and overlapping services are common. Cloud cost management alone highlights where money is going, but without optimization, those inefficiencies remain unaddressed.
The strategic value of Cloud cost optimization lies in what it unlocks. By improving financial predictability, companies can reallocate savings into innovation, scale new workloads such as AI and advanced analytics, and ensure that performance isn’t sacrificed under budget pressure. Organizations that treat optimization as a governance discipline — not just a finance task — gain the ability to align cloud spending with long-term business priorities.
Cloud cost optimization requires more than one tactic. It’s a discipline that combines monitoring, automation, governance, and financial accountability. The strategies below target the most common sources of waste — compute, storage, networking, and licensing — and demonstrate how to align resources with business goals without compromising performance.
Every major provider has native tools for this (AWS Cost Explorer, Azure Cost Management, Google Cloud Billing). They’re useful, but fall short in multi-cloud environments. That’s where third-party monitoring tools come in. Services like CloudHealth, Datadog, and Anodot specialize in anomaly detection, catching unusual spikes that could point to a misconfiguration, an exposed credential, or just a test environment left running too long.
Good governance means catching issues before they snowball. Budget alerts can be set at the project or account level so teams get notified when spend crosses a threshold. Layering in anomaly detection takes it further — flagging unexpected jumps in near real time so action happens before the bill goes out.
Regular monitoring isn’t just bookkeeping. It’s the feedback loop that keeps optimization work from unraveling over time.
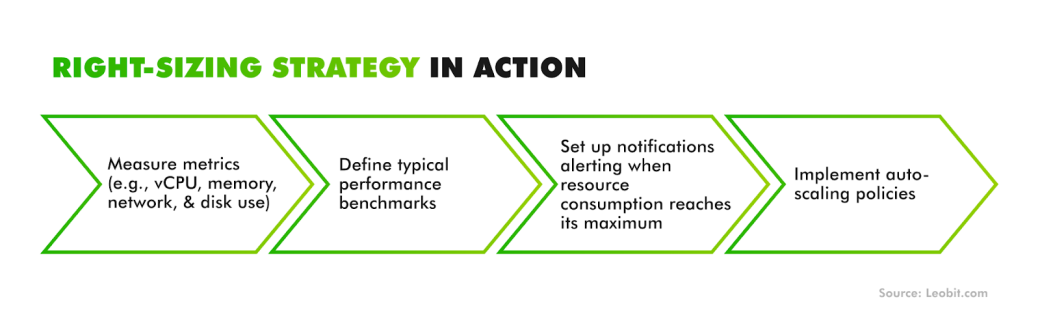
Right-sizing is the process of aligning your cloud computing resources with actual capacity requirements to ensure you’re not overpaying for unused infrastructure or risking performance issues due to under-provisioning.
Oversized instances drain budgets; undersized ones create performance issues. The fix is continuous right-sizing — watching CPU, memory, and I/O metrics and adjusting capacity as patterns change. Native auto-scaling groups, Kubernetes vertical pod autoscalers, and third-party platforms can handle much of this automatically.
Another common leak is non-production environments left running around the clock. Development, test, and staging workloads often don’t need to stay up outside business hours. Scheduling tools such as AWS Instance Scheduler, Azure Automation, or open-source options like Cloud Custodian can shut them down overnight or on weekends, often reducing costs by 30% or more.
Used together, right-sizing and off-hours scheduling keep infrastructure lean: resources scale when demand rises and shut down when they’re not needed.
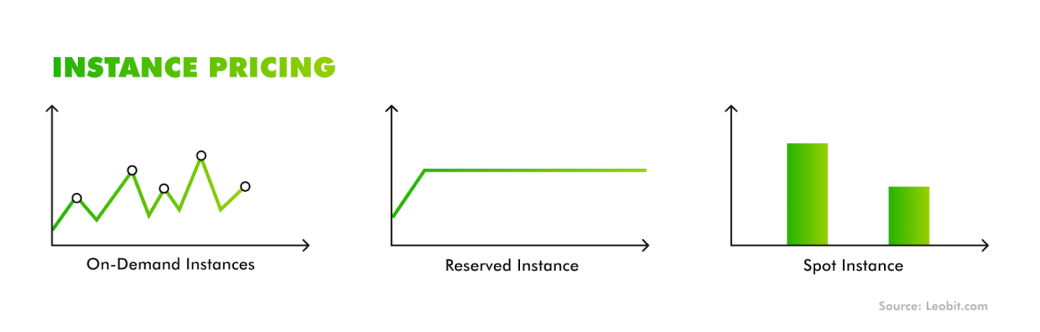
On-demand pricing maximizes flexibility but is the costliest model. Providers offer commitment-based discounts to offset this, and choosing the right one depends on workload predictability.
Decision Guide:
Optimization often involves mixing models — using RIs or Savings Plans for baseline demand and Spot for overflow. The key is continuous monitoring of usage patterns so commitments align with actual demand.
Data transfer fees can quietly become one of the largest line items on a cloud bill. Costs spike when traffic leaves the provider’s network, especially across regions or when moving data between clouds.
There are several ways to bring those charges down. The simplest is architectural: keep workloads and data in the same region whenever possible. For predictable, high-volume transfers, private connections such as AWS Direct Connect, Azure ExpressRoute, or Google Cloud Interconnect often cost less than standard egress rates. Caching and compression reduce the amount of data that needs to move in the first place, while CDNs like Cloudflare or Akamai can absorb the heaviest traffic at the edge.
Teams that factor network design into their cost strategy not only reduce costs but also improve latency and end-user experience.
Storage costs don’t stay small once an environment scales. Bills rise quickly if everything remains in the most expensive tier. Hot or Standard storage is built for data that needs constant access and low latency. Cool or Infrequent Access is cheaper but charges retrieval fees, while Archive or Cold tiers offer the lowest price with the trade-off of slower recovery and added access costs.
The way to control spend is to treat storage as a lifecycle problem. Data that starts in Hot can move down to cheaper tiers as it ages. Snapshots and volumes tied to terminated instances should be cleared out to avoid unnecessary accumulation. When retention policies are written against business needs — not just technical defaults — teams avoid paying for performance they don’t use.
Multi-cloud adoption is rising, but it complicates cost optimization. HashiCorp’s 2025 Cloud Complexity Report shows that 98% of organizations face cost challenges in multi-cloud environments, largely due to inconsistent governance.
A cost-aware multi-cloud strategy weighs trade-offs: single-cloud offers simpler billing and better volume discounts, while multi-cloud improves resilience and bargaining power. Cloud-native cost-aware design — using serverless, containers, and auto-scaling — helps regardless of provider. Key patterns include designing stateless workloads that can shift between providers and building observability into every layer.
The decision isn’t binary. Many organizations run mission-critical workloads on a primary provider while placing ancillary services elsewhere to balance risk and cost.
Cloud bills aren’t only about infrastructure. Software licenses — databases, middleware, developer tools — often hide in the spend. These costs are easy to overlook when bundled into managed services.
Optimization begins with discovery: identify licenses in use across cloud accounts. Track usage against entitlements to avoid over-purchasing. Where possible, negotiate enterprise agreements that align with actual consumption.
Teams should also evaluate whether bring-your-own-license (BYOL) models or cloud provider-managed options are more cost-effective. License mismanagement leads to both compliance risks and unnecessary spend, making this an essential part of a holistic Cloud cost optimization strategy.
Flexera’s State of the Cloud Report 2025 notes that organizations with dedicated FinOps teams grew from 51% to 59% in one year. The shift reflects the recognition that ad hoc savings aren’t enough — cost optimization requires cultural change.
Mature FinOps practices follow three phases:
Governance guardrails strengthen and secure this process. Policy-as-code can enforce budget caps, prohibit unapproved instance types, and require tags for cost allocation. By embedding these policies into CI/CD pipelines, organizations ensure optimization happens continuously, not just during quarterly reviews.
Optimization depends on both culture and tooling. A good starting point is tagging. Consistent resource tagging makes it possible to trace spend back to owners, projects, and functions. A basic schema might include tags like: team=marketing, environment=dev/test/prod, campaign=Q3launch, and costcenter=1234. These tags feed into reporting and ensure accountability across departments.
Forecasting is another critical piece. Even simple models built in spreadsheets can help teams project spend under different growth scenarios — for example, traffic increasing 15% quarter over quarter or launching into a new region. These forecasts tie directly into KPI mapping. When cloud usage is connected to business metrics like cost per lead or cost per acquisition, finance teams can see how optimization impacts marketing ROI.
Finally, cost optimization includes negotiation. Most major providers offer committed-use discounts, private pricing agreements, or enterprise contracts. Marketers should work with procurement and engineering leaders to consolidate usage data, model commitments realistically, and approach providers with evidence of sustained consumption. This is where optimization moves beyond trimming waste to securing structural savings.
No single tactic works for every workload. Use reserved instances or savings plans for predictable, always-on applications; spot instances for batch or flexible jobs; right-sizing and off-hours scheduling for development and test environments; storage tiering for archival data; and bandwidth optimization when egress fees dominate spend.
Begin with visibility — tagging resources, setting budget alerts, and enabling anomaly detection. Then layer in right-sizing, storage lifecycle policies, and off-hours automation. Each step builds discipline without disrupting core operations.
Sustaining those gains takes structure. Flexera’s 2025 report shows that companies with active FinOps practices are the ones that continue to improve year after year. The reason is simple — finance, engineering, and operations stay in lockstep. When those groups work together, cost optimization becomes part of normal operations rather than a clean-up exercise after budgets run hot.
Start with simple scenario planning. Spreadsheet models or native provider calculators can project spend under different growth rates, new deployments, or regional expansions. These forecasts help teams test best- and worst-case scenarios before costs are incurred.
Cloud cost management tracks and reports expenses — showing what was spent and by whom. Cloud cost optimization refines workloads and policies to ensure those expenses deliver maximum value. Cost management informs; optimization transforms.
Every major cloud platform offers native budget alerts. AWS Budgets, Azure Cost Management, and Google Cloud Billing all let you set thresholds by project or account so teams get notified as your spending approaches a limit. For larger or multi-cloud environments, third-party tools like Datadog or Anodot add anomaly detection, flagging sudden spikes that may point to a misconfiguration or runaway process. The goal isn’t just to stop overspending after the fact — it’s to give engineers an early signal so they can fix the problem before it turns into a shocking invoice.
Yes. AWS Instance Scheduler, Azure Automation, and Cloud Custodian are commonly used to shut down non-production environments during nights and weekends. Policies can be tuned to restart resources at set times to balance savings with developer productivity.
Cloud providers respond to evidence of steady, predictable spending. Start by pulling usage data across teams and regions to show the scale of your commitment. With that in hand, you can qualify for enterprise agreements or committed-use discounts, and in some cases negotiate private pricing. The more reliable your consumption profile looks, the stronger your position in those discussions.

