
How to Vet a Software Development Agency in 2026: 8 Signals That Actually Predict Project Success
Does the agency live up to its proposal? These eight signals help you tell the difference before you sign anything.
Updated March 26, 2026

Stop treating your 15-year-old SQL database like an AI prompt contract. This guide outlines the exact custom API architecture and data engineering foundations required to deploy LLMs without breaking your legacy systems.
Plugging a large language model (LLM) straight into a legacy SQL database is the fastest way to get a demo and the fastest way to get slow queries, brittle answers, and confidently wrong output. This guide explains the LLM integration trap, the middleware strategy that avoids it, and why data engineering has to come before your AI rollout.
If your team delivers web development services or builds internal tools, you’ve already seen the pattern: the simple integration is never simple in production. LLMs are no different. Teams are moving from chatbot experiments to AI agents, which are advanced systems that can fetch key performance indicators (KPIs), answer operational questions, and trigger workflows.
Looking for a Software Development agency?
Compare our list of top Software Development companies near you
AI is moving past experimentation. In McKinsey’s State of AI 2025 survey, 23% of respondents say their organizations are already scaling an agentic AI system, and another 39% are experimenting with AI agents.
At the same time, enterprise teams are feeling pressure to turn pilots into outcomes. Yet, a widely circulated MIT NANDA report argues that 95% of organizations have seen no measurable P&L impact from GenAI so far.
A big reason is data. In Salesforce’s latest State of Data & Analytics research, leaders estimate 26% of their data is untrustworthy, and 42% lack full confidence in the accuracy and relevance of AI outputs.
That’s the backdrop for the biggest mistake teams make:
Treating the database like an API contract and letting an LLM figure it out.
The trap usually looks like this:
It works until real traffic and real ambiguity show up.
Legacy SQL systems were tuned for predictable application queries. LLMs query differently:
Even when the SQL is correct, it’s often inefficient. In Tinybird’s analytical SQL benchmark, some models produced functional queries while reading substantially more data than a human-written query; one model read 32% more data on average.
Many organizations still run mission-critical workloads on old systems with fragile constraints and undocumented rules. The U.S. Government Accountability Office documented 10 critical federal legacy systems ranging from about 8 to 51 years old, collectively costing about $337 million annually to operate and maintain.
LLMs don’t know your organization’s unwritten rules about what queries are safe. They will stress your weakest link unless you design for it.
Hallucinations aren’t only the model making things up. They often happen when the system can’t confidently ground the answer in clean, consistent truth.
Legacy SQL environments amplify ambiguity:
A widely cited academic overview, A Survey on Hallucination in Large Language Models (ACM, 2025), catalogues common causes and mitigation strategies across LLM systems, including how missing context and weak grounding contribute to hallucination risk.
Most connectors assume prompt rules + role permissions are enough.
But SQL is not a stable interface contract. It’s an implementation detail.
If you give an LLM raw table access, you inherit:
In Snowflake’s engineering evaluation of text-to-SQL for BI, the team tested a single-shot approach using GPT-4o for SQL generation. On Snowflake’s more realistic evaluation set, they reported that accuracy dropped to 51%.
What’s more useful than the number is why it failed, because it mirrors what enterprise teams see in production:
Snowflake shows an example where the model chose Christmas Day 2022 when the question didn’t specify a year. That’s not random; it’s the model trying to complete an ambiguous request with a plausible assumption. In BI, plausible assumptions are how trust quietly dies.
Snowflake highlights scenarios where a query can be syntactically valid yet numerically incorrect, such as using window functions in ways that break when dates are non-consecutive. The output looks professional, so users don’t immediately suspect a problem.
In BI, correct SQL often depends on organization-specific definitions (what counts as revenue, which transactions qualify, what exclusions apply). A model can’t reliably infer that from raw tables and column names.
What fixed it: Snowflake’s approach (Cortex Analyst) relies on a semantic model, explicit definitions of entities, relationships, and measures, so the system stops guessing what metrics mean. Instead of letting the model roam your schema, you give it a governed map of reality.
That’s the same principle behind the middleware translator strategy below.
If you want LLMs to work reliably with legacy systems, don’t let them talk directly to the database. Give them a translator: a modern API layer that speaks both languages.
This is exactly where custom API development services earn their keep: you’re not adding an AI feature, you’re building a governed contract between unpredictable natural language and a database that was never designed for it.
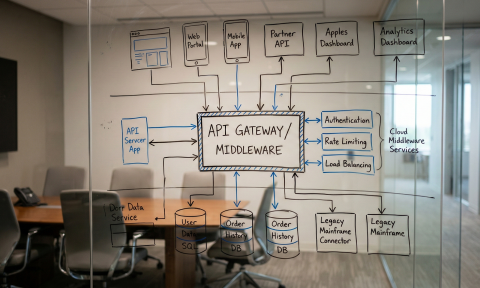
A production-grade middleware layer turns raw data into stable, governed capabilities. In practice, that means:
This is where custom software development pays off. Off-the-shelf connectors can’t encode your definitions, guardrails, and performance constraints. A purpose-built layer can.
The highest-leverage guardrails are simple, but they must be enforced in code:
A helpful mental model: the LLM should be your orchestrator, not your database optimizer.
You can’t prompt your way out of bad data.
And most organizations still struggle with data integrity. Precisely’s survey work found data quality remains the top data integrity challenge, with 64% of respondents naming it as the biggest issue (up from 50% the year before).
Salesforce’s research reinforces the point: a meaningful chunk of enterprise data is still considered untrustworthy, and leaders feel AI increases the urgency to fix foundations.
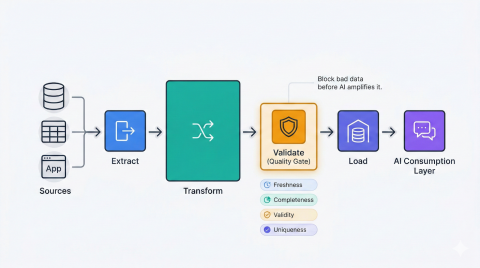
Treat data quality like software quality:
If you add LLM agents before fixing this, you’re automating the spread of bad data.
Pick one definition and enforce it everywhere. If finance and marketing compute active customers differently, your assistant will contradict itself, and users will stop using it.
AI needs context. Humans do too.
At a minimum, ensure every critical dataset has:
This also improves governance and incident response.
Before you let an LLM answer from enterprise data, make sure you have:
If you only do one thing, build the evaluation suite. It’s how you move from “the demo feels right” to “the system is measurably correct.”
A practical sequence that works well in legacy environments:
Pick a narrow, high-frequency workflow (invoice questions, order status, support triage). Define the top questions and success metrics (accuracy, latency, escalation reduction).
Create the translator API for that workflow, add caching and limits, and keep SQL access template-driven.
Policies, SOPs, and product docs often answer half the questions users ask. RAG helps ground responses in that text and reduces hallucination risk.
Track accuracy against your evaluation suite, plus system metrics: DB load, query timeouts, and user rework time. This is also where many teams lean on enterprise AI integration to pressure-test governance, evaluation, and production safety before rolling out to more departments.
When you get this right, the upside is real. OpenAI’s enterprise report summarizes surveyed workers reporting speed/quality improvements and time saved per day, but capturing that value depends on making AI usable inside real systems.

